9 Reasons AI Isn't Citing Your Content (and How to Fix Each)

Table of Contents +
- How AI engines actually pick sources
- 1. Is your domain authority too low?
- 2. Are you blocking the AI crawlers?
- 3. Is your answer buried instead of up front?
- 4. Is your schema missing or mismatched?
- 5. Do you cite statistics and sources?
- 6. Is your content stale?
- 7. Is your off-site brand presence too weak?
- 8. Are you using the wrong content format?
- 9. Is your topical coverage too thin?
- The nine reasons at a glance
- References
9 reasons AI isn't citing your content: low domain authority, blocked crawlers, buried answers, weak brand mentions (0.664 correlation), and the fix for each.
TL;DR: AI engines skip your content for fixable reasons. The three biggest: you do not rank in the top 10 (about half of all AI citations come from there), you bury the answer instead of leading with a 40-80 word capsule, and you have weak off-site brand mentions (the single strongest citation signal, correlation 0.664). Fix structure, freshness, and authority and citations follow.
You publish solid content. People read it. But when you ask ChatGPT, Perplexity, or Google's AI Overviews a question your article answers perfectly, your URL is nowhere in the cited sources. Someone else gets the link, the traffic, and the trust.
This is not bad luck. AI engines select sources using a different ruleset than the blue-link era. The good news: the ruleset is knowable, and most gaps are structural. Below are the nine most common reasons your content gets skipped, each with the specific fix.
How AI engines actually pick sources
AI answer engines work in two stages. First they retrieve a pool of candidate pages, then they cite only a fraction of that pool in the final answer. ChatGPT cites roughly 15% of the pages it retrieves[1], which means even a retrieved page loses four times out of five. Each of the nine reasons below blocks you at one of those two stages: either your page never enters the candidate pool, or it enters but loses the selection step to a better-structured source. Knowing which stage you are failing at tells you which fix to ship first. As a rule of thumb, reasons 1, 2, and 9 keep you out of the candidate pool, while reasons 3 through 8 lose you the selection step once you are in it. Our generative engine optimization guide covers the full framework.

GetTraffic writes and publishes SEO content automatically - articles that build authority and drive organic traffic - start your free trial.
1. Is your domain authority too low?
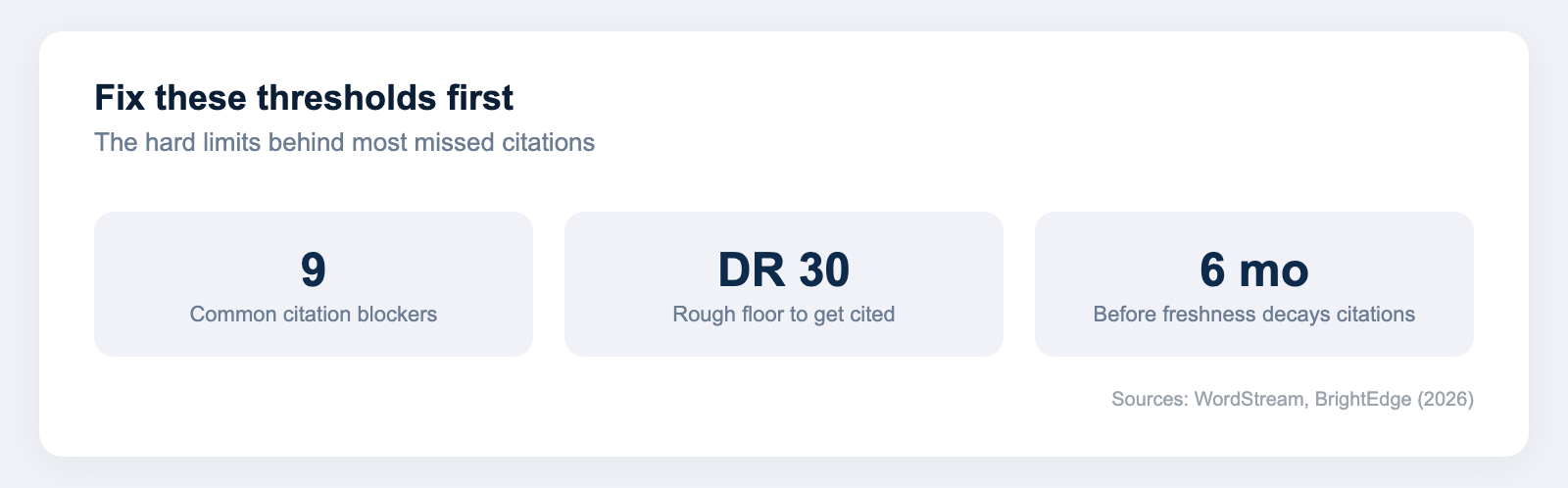
About half of AI-cited sources rank in the top 10 organic results for the same query[2]. AI engines lean on existing search rankings as a fast trust proxy, so position feeds directly into the candidate pool. Sites with a domain rating under 30 are rarely cited at all[2]. If you do not rank, you are not retrieved, and you cannot be cited.
The fix:
- Pull every page currently sitting in positions 4 to 15 and reinforce those first - they are one push away from the top-10 citation threshold, so they return value fastest.
- Add real topical depth and earned links to those near-miss pages instead of publishing new one-off posts that start from zero.
- Pick a small set of head queries you actually want to be cited for and concentrate authority there rather than spreading effort thin across dozens of keywords.
2. Are you blocking the AI crawlers?
Each AI platform runs its own crawler with its own user agent, and a single disallow line in robots.txt removes you from that platform entirely, no matter how good the content is[3]. ChatGPT Search is Bing-index dependent[1], so if Bing has never indexed you, ChatGPT cannot surface you even when your robots.txt is wide open. This is the most common silent failure.
The fix:
- Open robots.txt and confirm you explicitly allow GPTBot, OAI-SearchBot, PerplexityBot, ClaudeBot, and Google-Extended - allow only the agents that fit your content policy, but do it on purpose, not by accident.
- Add your site to Bing Webmaster Tools and confirm the pages you care about are actually in the Bing index, since that gates ChatGPT.
- Check that no firewall, CDN rule, or bot-management product is rate-limiting or returning 403 to those user agents above the robots.txt layer.
3. Is your answer buried instead of up front?
AI engines extract a concise, liftable answer; they do not read to the end of a slow build-up. Perplexity favors a 40-80 word answer capsule placed near the top of the page[3]. Google's AI Overviews prefer self-contained passages of roughly 134-167 words, and content scoring 8.5 or higher on semantic completeness is about 4.2x more likely to be cited[4]. If your real answer arrives in paragraph six, the engine never reaches it.
The fix:
- Open each section with a direct, complete answer in 40-80 words, then expand below it - put the conclusion before the reasoning, not after.
- Make every passage pass a standalone test: if it were lifted out with no surrounding paragraphs, it should still fully answer the question.
- Match the heading to the exact question a user types, so the engine can map query to capsule. See how to optimize content for Perplexity for capsule patterns.
4. Is your schema missing or mismatched?
Structured data tells engines what your content is before they parse the prose, and it measurably moves citation odds. FAQPage schema sits among the highest AI citation rates, and adding accurate schema can raise selection probability by around 73%[3]. But mismatched schema is worse than none: when your markup describes something the page does not actually contain, engines read it as manipulation and discount the whole page[2].
The fix:
- Add Article, FAQPage, and HowTo schema that mirrors what is visibly on the page - every FAQ question and every step must exist in the body text.
- Run each template through Google's Rich Results Test and Schema.org validator before publishing, and re-validate after any content edit.
- Delete legacy or auto-generated markup that no longer matches the current page rather than leaving stale objects behind.
5. Do you cite statistics and sources?
Content that backs claims with evidence is cited more often, because engines and their training pipelines treat verifiable claims as higher trust. The Princeton GEO study found that adding citations to sources lifts visibility in AI answers by about 40%, adding statistics by 37%, and adding quotations by 30%[5]. The same study found keyword stuffing cuts visibility by about 10%[5]. Generic, unsupported prose reads as low-trust filler.
The fix:
- Attach a specific number, a named source, or a direct quote to every load-bearing claim instead of asserting it bare.
- Link to the original source, not to an aggregator that re-reports it, so the engine can trace the claim back to its origin.
- Strip repeated exact-match keywords; they actively suppress AI visibility. This is also why thin, templated text underperforms - more in why generic AI content fails.
6. Is your content stale?
Freshness is a live ranking input for AI engines, not a cosmetic detail. Perplexity reviews evergreen pages roughly every 14 days and rewards content that has been recently updated and stays accurate[3]. A page that has not changed in two years signals decay, and the engine will reach for a competitor's current take instead, even if your original was stronger when it shipped.
The fix:
- Put a recurring refresh date on your priority pages and treat it like a deadline, not a someday task.
- On each refresh, update the statistics, the dates, and the examples to the current year, and remove anything that has since been superseded.
- Make the change substantive enough to matter - editing a timestamp without changing the body does not register as a real update.
SEO content that ranks, written and published for you
GetTraffic creates authority-building content clusters for your business. No writing, no freelancers, no content calendar. Agency-quality results at 91% less cost.
Start My Free Trial7. Is your off-site brand presence too weak?
The strongest off-site citation signal is how often your brand is mentioned across the web. Brand mentions correlate at 0.664 with citation probability, the highest single correlation measured among the studied factors[2]. The most common GEO mistake is ignoring this entirely and optimizing only the on-page layer[2]. Engines treat a brand the wider web talks about as inherently more trustworthy.
The fix:
- Get named in the sources AI actually crawls: industry roundups, podcast show notes, reputable directories, and partner sites.
- Contribute expert comments and quotes to publications in your space - unlinked brand mentions still count toward this signal.
- Keep the brand name and description consistent everywhere it appears so the mentions reinforce one entity rather than fragmenting. See how to get cited by ChatGPT for the off-site playbook.
8. Are you using the wrong content format?
Format predicts citation share more than most writers expect. Comparison content captures roughly 33% of citations, guides about 15%, original research around 12%, and listicles about 10%[5]. A wall of generic prose competes for the smallest slice, and the format has to match the intent behind the query: a buyer weighing options will not be answered by a definition post.
The fix:
- For decision-stage queries where people compare options, build a dedicated comparison page rather than a general overview - it earns the largest citation share by far.
- Turn how-to and explainer topics into structured guides with clear steps and headings instead of flowing narrative prose.
- Publish at least one piece of original research or proprietary data per cluster; first-party numbers get cited because no competitor can copy them. If you sell against alternatives, see our comparison of AI SEO tools.
9. Is your topical coverage too thin?
One good article on a topic rarely earns authority. AI engines reward sites that cover a subject deeply across many connected pages, because that breadth and internal linking signal genuine expertise rather than a drive-by post. A single article surrounded by silence reads as shallow next to a competitor that has published a full interlinked cluster on the same subject and keeps it current.
The fix:
- Build a pillar page on the core topic, then surround it with supporting articles that cover the subtopics and questions end to end.
- Interlink the cluster tightly - every supporting post links up to the pillar and across to its siblings - so engines read the set as one authoritative body of work.
- Maintain the whole cluster on a refresh cadence, not just the pillar, so coverage stays current across the topic. Doing this by hand is slow, which is why GetTraffic generates industry-specific clusters with answer capsules, accurate schema, and a built-in refresh cadence, then auto-publishes to your CMS - addressing reasons 3, 4, 6, 8, and 9 structurally.
The nine reasons at a glance
| Reason | Fix |
|---|---|
| Domain authority too low | Earn top-10 rankings with real depth and links |
| Blocking AI crawlers | Allow AI bots in robots.txt; index in Bing |
| Answer buried | Lead with a 40-80 word answer capsule |
| Schema missing or mismatched | Add accurate Article/FAQ/HowTo schema |
| No statistics or citations | Back claims with numbers, sources, quotes |
| Stale content | Refresh priority pages on a schedule |
| Weak off-site brand presence | Earn third-party mentions across the web |
| Wrong content format | Use comparison, guide, research formats |
| Thin topical coverage | Build interlinked topical clusters |
Work through these in order of leverage. Crawler access, accurate schema, and answer capsules are quick wins you can ship this week, and they often move citation rates within a single Perplexity review cycle. Domain authority, off-site brand mentions, and cluster depth are the slow compounding work that decides whether you get cited at scale over the following quarters. Most teams fix the cheap structural reasons, see early lift, and assume they are done - then stall because they never invest in the authority signals that decide the larger queries. For the technical layer, check whether an llms.txt file actually helps and how E-E-A-T applies to AI content.
References
- Erlin.ai (2026). ChatGPT Search Optimization. erlin.ai
- WordStream (2026). How to Get Cited by AI Search. wordstream.com
- ZipTie (2026). How to Optimize Content for Perplexity AI. ziptie.dev
- Pepper Content (2026). How to Rank in Google AI Overviews: The 2026 Playbook. pepper.inc
- Aggarwal et al. (2023). GEO: Generative Engine Optimization. arxiv.org
Frequently Asked Questions
Why isn't my content cited by AI engines?
How do I know if I'm blocking AI crawlers?
Does schema markup help AI cite my content?
What content format gets cited most by AI?
How often should I update content to stay cited?
Get your business on page 1 of Google
Get your business found on Google - SEO content written and published automatically.
Start My Free Trial7-day trial - cancel anytime


